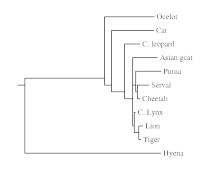
The tips of a phylogenetic tree can be living
taxa or
fossils, and represent the "end" or the present time in an evolutionary lineage. A phylogenetic diagram can be rooted or unrooted. A rooted tree diagram indicates the hypothetical
common ancestor of the tree. An unrooted tree diagram (a network) makes no assumption about the ancestral line, and does not show the origin or "root" of the taxa in question or the direction of inferred evolutionary transformations.[5]
In addition to their use for inferring phylogenetic patterns among taxa, phylogenetic analyses are often employed to represent relationships among genes or individual organisms. Such uses have become central to understanding
biodiversity, evolution,
ecology, and
genomes.
Phylogenetics is component of
systematics that uses similarities and differences of the characteristics of species to interpret their evolutionary relationships and origins. Phylogenetics focuses on whether the characteristics of a species reinforce a phylogenetic inference that it diverged from the most recent common ancestor of a taxonomic group.[6]
In the field of
cancer research, phylogenetics can be used to study the clonal evolution of
tumors and molecular
chronology, predicting and showing how cell populations vary throughout the progression of the disease and during treatment, using whole
genome sequencing techniques.[7] The evolutionary processes behind cancer progression are quite different from those in species and are important to phylogenetic inference; these differences manifest in at least four areas: the types of aberrations that occur, the rates of
mutation, the intensity, and high heterogeneity - variability - of tumor cell subclones.[8]
Phylogenetics can also aid in
drug design and discovery. Phylogenetics allows scientists to organize species and can show which species are likely to have inherited particular traits that are medically useful, such as producing biologically active compounds - those that have effects on the human body. For example, in drug discovery,
venom-producing animals are particularly useful. Venoms from these animals produce several important drugs, e.g.,
ACE inhibitors and Prialt (
Ziconotide). To find new venoms, scientists turn to phylogenetics to screen for closely related species that may have the same useful traits. The phylogenetic tree shows which species of
fish have an origin of venom, and related fish they may contain the trait. Using this approach in studying venomous fish, biologists are able to identify the fish species that may be venomous. Biologist have used this approach in many species such as snakes and lizards.[9]
In
forensic science, phylogenetic tools are useful to assess DNA evidence for court cases. The simple phylogenetic tree of viruses A-E shows the relationships between viruses e.g., all viruses are descendants of Virus A.
HIV forensics uses phylogenetic analysis to track the differences in HIV genes and determine the relatedness of two samples. Phylogenetic analysis has been used in criminal trials to exonerate or hold individuals. HIV forensics does have its limitations, i.e., it cannot be the sole proof of transmission between individuals and phylogenetic analysis which shows transmission relatedness does not indicate direction of transmission.[10]
One small clade of fish, showing how venom has evolved multiple times.[9]
Taxonomy is the identification, naming, and
classification of organisms. Compared to systemization, classification emphasizes whether a species has characteristics of a taxonomic group.[6] The
Linnaean classification system developed in the 1700s by
Carolus Linnaeus is the foundation for modern classification methods. Linnaean classification relies on an organism's phenotype or physical characteristics to group and organize species.[11] With the emergence of
biochemistry, organism classifications are now usually based on phylogenetic data, and many systematists contend that only
monophyletic taxa should be recognized as named groups. The degree to which classification depends on inferred evolutionary history differs depending on the school of taxonomy:
phenetics ignores phylogenetic speculation altogether, trying to represent the similarity between organisms instead;
cladistics (phylogenetic systematics) tries to reflect phylogeny in its classifications by only recognizing groups based on shared, derived characters (
synapomorphies);
evolutionary taxonomy tries to take into account both the branching pattern and "degree of difference" to find a compromise between them.
Phenetics, popular in the mid-20th century but now largely obsolete, used
distance matrix-based methods to construct trees based on overall similarity in
morphology or similar observable traits (i.e. in the
phenotype or the
overall similarity of DNA, not the
DNA sequence), which was often assumed to approximate phylogenetic relationships.
Prior to 1950, phylogenetic inferences were generally presented as
narrative scenarios. Such methods are often ambiguous and lack explicit criteria for evaluating alternative hypotheses.[13][14][15]
Impacts of taxon sampling
In phylogenetic analysis, taxon sampling selects a small group of taxa to represent the evolutionary history of its broader population.[16] This process is also known as
stratified sampling or clade-based sampling.[17] The practice occurs given limited resources to compare and analyze every species within a target population.[16] Based on the representative group selected, the construction and accuracy of phylogenetic trees vary, which impacts derived phylogenetic inferences.[17]
Unavailable datasets, such as an organism's incomplete DNA and protein amino acid sequences in genomic databases, directly restrict taxonomic sampling.[17] Consequently, a significant source of
error within phylogenetic analysis occurs due to inadequate taxon samples. Accuracy may be improved by increasing the number of genetic samples within its monophyletic group. Conversely, increasing sampling from outgroups extraneous to the target stratified population may decrease accuracy.
Long branch attraction is an attributed theory for this occurrence, where nonrelated branches are incorrectly classified together, insinuating a shared evolutionary history.[16]
Percentage of inter-ordinal branches reconstructed with a constant number of bases and four phylogenetic tree construction models; neighbor-joining (NJ), minimum evolution (ME), unweighted maximum parsimony (MP), and maximum likelihood (ML). Demonstrates phylogenetic analysis with fewer taxa and more genes per taxon matches more often with the replicable consensus tree. The dotted line demonstrates an equal accuracy increase between the two taxon sampling methods. Figure is property of Michael S. Rosenberg and Sudhir Kumar as presented in the journal article Taxon Sampling, Bioinformatics, and Phylogenomics.[17]
There are debates if increasing the number of taxa sampled improves phylogenetic accuracy more than increasing the number of genes sampled per taxon. Differences in each method's sampling impact the number of nucleotide sites utilized in a sequence alignment, which may contribute to disagreements. For example, phylogenetic trees constructed utilizing a more significant number of total nucleotides are generally more accurate, as supported by phylogenetic trees' bootstrapping replicability from random sampling.
The graphic presented in Taxon Sampling, Bioinformatics, and Phylogenomics, compares the correctness of phylogenetic trees generated using fewer taxa and more sites per taxon on the x-axis to more taxa and fewer sites per taxon on the y-axis. With fewer taxa, more genes are sampled amongst the taxonomic group; in comparison, with more taxa added to the taxonomic sampling group, fewer genes are sampled. Each method has the same total number of nucleotide sites sampled. Furthermore, the dotted line represents a 1:1 accuracy between the two sampling methods. As seen in the graphic, most of the plotted points are located below the dotted line, which indicates gravitation toward increased accuracy when sampling fewer taxa with more sites per taxon. The research performed utilizes four different phylogenetic tree construction models to verify the theory; neighbor-joining (NJ), minimum evolution (ME), unweighted maximum parsimony (MP), and maximum likelihood (ML). In the majority of models, sampling fewer taxon with more sites per taxon demonstrated higher accuracy.
Generally, with the alignment of a relatively equal number of total nucleotide sites, sampling more genes per taxon has higher bootstrapping replicability than sampling more taxa. However, unbalanced datasets within genomic databases make increasing the gene comparison per taxon in uncommonly sampled organisms increasingly difficult.[17]
History
Overview
The term "phylogeny" derives from the German Phylogenie, introduced by Haeckel in 1866,[18] and the
Darwinian approach to classification became known as the "phyletic" approach.[19] It can be traced back to
Aristotle, who wrote in his Posterior Analytics, "We may assume the superiority ceteris paribus [other things being equal] of the demonstration which derives from fewer postulates or hypotheses."
Ernst Haeckel's recapitulation theory
The modern concept of phylogenetics evolved primarily as a disproof of a previously widely accepted theory. During the late 19th century,
Ernst Haeckel's
recapitulation theory, or "biogenetic fundamental law", was widely accepted. It was often expressed as "
ontogeny recapitulates phylogeny", i.e. the development of a single organism during its lifetime, from germ to adult, successively mirrors the adult stages of successive ancestors of the species to which it belongs. But this theory has long been rejected.[20][21] Instead,
ontogeny evolves – the phylogenetic history of a species cannot be read directly from its ontogeny, as Haeckel thought would be possible, but characters from ontogeny can be (and have been) used as data for phylogenetic analyses; the more closely related two species are, the more
apomorphies their embryos share.
Timeline of key points
Branching tree diagram from Heinrich Georg Bronn's work (1858)Phylogenetic tree suggested by Haeckel (1866)
14th century, lex parsimoniae (
parsimony principle),
William of Ockam, English philosopher, theologian, and Franciscan friar, but the idea actually goes back to
Aristotle, as a precursor concept. He introduced the concept of
Occam's razor, which is the problem solving principle that recommends searching for explanations constructed with the smallest possible set of elements. Though he did not use these exact words, the principle can be summarized as "Entities must not be multiplied beyond necessity." The principle advocates that when presented with competing hypotheses about the same prediction, one should prefer the one that requires fewest assumptions.
1763,
Bayesian probability, Rev. Thomas Bayes,[22] a precursor concept. Bayesian probability began a resurgence in the 1950s, allowing scientists in the computing field to pair traditional Bayesian statistics with other more modern techniques. It is now used as a blanket term for several related interpretations of probability as an amount of epistemic confidence.
18th century, Pierre Simon (Marquis de Laplace), perhaps first to use ML (maximum likelihood), precursor concept. His work gave way to the
Laplace distribution, which can be directly linked to
least absolute deviations.
1809, evolutionary theory, Philosophie Zoologique,Jean-Baptiste de Lamarck, precursor concept, foreshadowed in the 17th century and 18th century by Voltaire, Descartes, and Leibniz, with Leibniz even proposing evolutionary changes to account for observed gaps suggesting that many species had become extinct, others transformed, and different species that share common traits may have at one time been a single race,[23] also foreshadowed by some early Greek philosophers such as
Anaximander in the 6th century BC and the atomists of the 5th century BC, who proposed rudimentary theories of evolution[24]
1837, Darwin's notebooks show an evolutionary tree[25]
1840, American Geologist Edward Hitchcock published what is considered to be the first paleontological "Tree of Life". Many critiques, modifications, and explanations would follow.[26]This chart displays one of the first published attempts at a paleontological "Tree of Life" by Geologist Edward Hitchcock. (1840)
1843, distinction between
homology and
analogy (the latter now referred to as
homoplasy), Richard Owen, precursor concept. Homology is the term used to characterize the similarity of features that can be parsimoniously explained by common ancestry. Homoplasy is the term used to describe a feature that has been gained or lost independently in separate lineages over the course of evolution.
1858, Paleontologist Heinrich Georg Bronn (1800–1862) published a hypothetical tree to illustrating the paleontological "arrival" of new, similar species. following the extinction of an older species. Bronn did not propose a mechanism responsible for such phenomena, precursor concept.[27]
1858, elaboration of evolutionary theory, Darwin and Wallace,[28] also in Origin of Species by Darwin the following year, precursor concept.
1866,
Ernst Haeckel, first publishes his phylogeny-based evolutionary tree, precursor concept. Haeckel introduces the now-disproved recapitulation theory.
1893,
Dollo's Law of Character State Irreversibility,[29] precursor concept. Dollo's Law of Irreversibility states that "an organism never comes back exactly to its previous state due to the indestructible nature of the past, it always retains some trace of the transitional stages through which it has passed."[30]
1912, ML (maximum likelihood recommended, analyzed, and popularized by
Ronald Fisher, precursor concept. Fisher is one of the main contributors to the early 20th-century revival of Darwinism, and has been called the "greatest of Darwin's successors" for his contributions to the revision of the theory of evolution and his use of mathematics to combine
Mendelian genetics and
natural selection in the
20th century "modern synthesis".
1921, Tillyard uses term "phylogenetic" and distinguishes between archaic and specialized characters in his classification system.[31]
1949,
Jackknife resampling, Maurice Quenouille (foreshadowed in '46 by Mahalanobis and extended in '58 by Tukey), precursor concept.
1950,
Willi Hennig's classic formalization.[32] Hennig is considered the founder of phylogenetic systematics, and published his first works in German of this year. He also asserted a version of the parsimony principle, stating that the presence of amorphous characters in different species 'is always reason for suspecting kinship, and that their origin by convergence should not be presumed a priori'. This has been considered a foundational view of
phylogenetic inference.
1952, William Wagner's ground plan divergence method.[33]
1960, "cladistic" coined by Cain and Harrison.[35]
1963, first attempt to use ML (maximum likelihood) for phylogenetics, Edwards and Cavalli-Sforza.[36]
1965
Camin-Sokal parsimony, first parsimony (optimization) criterion and first computer program/algorithm for cladistic analysis both by Camin and Sokal.[37]
Character compatibility method, also called clique analysis, introduced independently by Camin and Sokal (loc. cit.) and
E. O. Wilson.[38]
First successful application of ML (maximum likelihood) to phylogenetics (for protein sequences), Neyman.[44]
Fitch parsimony, Walter M. Fitch.[45] These gave way to the most basic ideas of
maximum parsimony. Fitch is known for his work on reconstructing phylogenetic trees from protein and DNA sequences. His definition of
orthologous sequences has been referenced in many research publications.
NNI (nearest neighbour interchange), first branch-swapping search strategy, developed independently by Robinson[46] and Moore et al.
ME (minimum evolution), Kidd and Sgaramella-Zonta[47] (it is unclear if this is the pairwise distance method or related to ML as Edwards and Cavalli-Sforza call ML "minimum evolution").
1980,
PHYLIP, first software package for phylogenetic analysis,
Joseph Felsenstein. A free computational phylogenetics package of programs for inferring evolutionary trees (
phylogenies). One such example tree created by PHILYP, called a "drawgram", generates rooted trees. This image shown in the figure below shows the evolution of phylogenetic trees over time.
Strict consensus, Sokal and Rohlf[55]This image depicts a PHILYP generated drawgram. This drawgram is an example of one of the possible trees the software is capable of generating.first computationally efficient ML (maximum likelihood) algorithm.[56] Felsenstein created the Felsenstein Maximum Likelihood method, used for the inference of phylogeny which evaluates a hypothesis about evolutionary history in terms of the probability that the proposed model and the hypothesized history would give rise to the observed data set.
1996, first working methods for BI (Bayesian Inference) independently developed by Li,[72] Mau,[73] and Rannala and Yang[74] and all using MCMC (Markov chain-Monte Carlo).
1998, TNT (Tree Analysis Using New Technology), Goloboff, Farris, and Nixon.
2004, 2005, similarity metric (using an approximation to Kolmogorov complexity) or NCD (normalized compression distance), Li et al.,[76] Cilibrasi and Vitanyi.[77]
Phylogenetic tools and representations (trees and networks) can also be applied to
philology, the study of the evolution of oral languages and written text and manuscripts, such as in the field of
quantitative comparative linguistics.[79]
Computational phylogenetics can be used to investigate a language as an evolutionary system. The evolution of human language closely corresponds with human's biological evolution which allows phylogenetic methods to be applied. The concept of a "tree" serves as an efficient way to represent relationships between languages and language splits. It also serves as a way of testing hypotheses about the connections and ages of language families. For example, relationships among languages can be shown by using
cognates as characters.[80][81] The phylogenetic tree of Indo-European languages shows the relationships between several of the languages in a timeline, as well as the similarity between words and word order.
There are three types of criticisms about using phylogenetics in philology, the first arguing that languages and species are different entities, therefore you can not use the same methods to study both. The second being how phylogenetic methods are being applied to linguistic data. And the third, discusses the types of data that is being used to construct the trees.[80]
Bayesian phylogenetic methods, which are sensitive to how treelike the data is, allow for the reconstruction of relationships among languages, locally and globally. The main two reasons for the use of Bayesian phylogenetics are that (1) diverse scenarios can be included in calculations and (2) the output is a sample of trees and not a single tree with true claim.[82]
The same process can be applied to texts and manuscripts. In
Paleography, the study of historical writings and manuscripts, texts were replicated by scribes who copied from their source and alterations - i.e., 'mutations' - occurred when the scribe did not precisely copy the source.[83]
Phylogenetic screens involve the pharmacological examination of closely related groups of organisms. Advances in
cladistics analysis through faster computer programs and improved molecular techniques have increased the precision of phylogenetic determination, allowing for the identification of species with pharmacological potential.
Phylogenetic screens have been used in a rudimentary manner in the past, such as studying the
Apocynaceae family of plants known for their alkaloid-producing species like
Catharanthus, which produces
vincristine, an antileukemia drug. However, modern techniques now enable researchers to study close relatives of a species to uncover either (1) higher abundance of important bioactive compounds (e.g., species of
Taxus for taxol) or (2) natural variants of known pharmaceuticals (e.g., species of Catharanthus for different forms of vincristine or vinblastine.[citation needed]
The figure below contains the phylogenetic screen of biodiversity within the fungi family. Inside the circle there are subtrees present that were done via phylogenetic analysis. These relations help understand the evolutionary history of various groups of organisms, identifying relationships between different species, and predicting future evolutionary changes. If we were to take biodiversity information from existing knowledge there might be relations between species or subgroups that we didn't know. But with emerging imagery systems and new analysis techniques more genetic relation can be found in biodiverse fields. The image below can help with conservation efforts as there are rare species of fungi involved, that could be beneficial to ecosystems all around.[84]
Phylogenetic Subtree of fungi containing different biodiverse sections of the fungi group.
Whole-genome sequence data of pathogens obtained from outbreaks or epidemics of infectious diseases can provide important insights into transmission dynamics and inform public health strategies. Previous studies have relied on integrating genomic and epidemiological data to reconstruct transmission events. However, recent research has explored the possibility of deducing transmission patterns solely from genomic data using
phylodynamics, which involves analyzing the properties of pathogen phylogenies. Phylodynamics uses theoretical models to compare predicted branch lengths with actual branch lengths in phylogenies to infer transmission patterns. Additionally,
coalescent theory, which describes probability distributions on trees based on population size, has been adapted for epidemiological purposes. Another potential source of information within phylogenies that has been explored is "tree shape". These approaches are computationally intensive but have the potential to provide valuable insights into pathogen transmission dynamics.[85]
Pathogen Transmission Trees
The structure of the host contact network has a profound impact on the dynamics of outbreaks or epidemics, and outbreak management strategies rely on the type of transmission patterns driving the outbreak. One can expect that pathogen genomes spreading through different contact network structures, such as chains, homogenous networks, or networks with super-spreaders, would accumulate mutations in distinct patterns, resulting in noticeable differences in the shape of phylogenetic trees, as illustrated in Fig. 1. Analyzation of the structural characteristics of phylogenetic trees generated from simulated bacterial genome evolution across multiple types of contact networks was conducted. Simple topological properties of phylogenetic trees that, when combined, can be used to classify trees into chain-like, homogenous, or super-spreading dynamics, revealing transmission dynamics. These properties form the basis of a computational classifier are used to classify real-world outbreaks. Remarkably, the computational predictions of overall transmission dynamics for each outbreak align with known epidemiology [86]
Graphical Representation of Phylogenetic Tree analysis
Different transmission networks result in quantitatively different tree shapes to determine whether tree shapes captured information about the underlying disease transmission patterns within an outbreak, we simulated evolution of a bacterial genome over three types of outbreak contact network—homogenous, super-spreading and chain—and summarized the resulting phylogenies with five metrics describing tree shape. Figures 2 and 3 illustrate the distributions of these metrics across the three types of outbreaks, revealing clear differences in tree topology depending on the underlying host contact network. Super-spreader networks gave rise to phylogenies with higher Colless imbalance, longer ladder patterns, lower Δw and deeper trees than transmission networks with a homogeneous distribution of contacts. Trees derived from chain-like networks were less variable, deeper, more imbalanced and narrower than the other trees. Other topological summary metrics considered did not resolve the three outbreak types as fully (Supplementary Information). Scatter plots can be used for pathogen transmission analysis to visualize the relationship between two variables, such as the number of infected individuals and the time since infection. For example, a scatter plot can be used to examine the relationship between the number of cases of a pathogen and the amount of time since the first case was reported. This can help to identify trends and patterns in the data, such as whether the spread of the pathogen is increasing or decreasing over time. Scatter plots can also be used to identify any outliers or clusters of data points, which can provide insight into potential transmission routes or super-spreader events. Overall, scatter plots can be a useful tool in pathogen transmission analysis to identify patterns and trends in the data, and to inform public health interventions and control measures.[86]
Pathogen Transfer Box Plot data
The
box plot imagery on the right displays the pathogen transformation data. Box plots are often used in statistical analysis to compare different groups or to visualize changes in a single group over time. They are particularly useful when dealing with large datasets or when comparing several groups, as they can quickly highlight differences or similarities in the data. Box plots, also known as box-and-whisker plots, are useful in statistical analysis to provide a summary of the distribution of a dataset. They display the range, median, quartiles, and potential outliers of the data in a visual manner. Box plots are commonly used to compare different groups or to analyze changes in a single group over time. They are especially helpful when working with large datasets or when comparing multiple groups, as they can easily identify any differences or similarities in the data. This makes box plots a valuable tool for analyzing pathogen transmission data, as they can help to identify important features in the distribution of the data.[86]
^Richard C. Brusca & Gary J. Brusca (2003). Invertebrates (2nd ed.). Sunderland, Massachusetts: Sinauer Associates.
ISBN978-0-87893-097-5.
^Bock, W. J. (2004). Explanations in systematics. Pp. 49–56. In Williams, D. M. and Forey, P. L. (eds) Milestones in Systematics. London: Systematics Association Special Volume Series 67. CRC Press, Boca Raton, Florida.
^Auyang, Sunny Y. (1998). Narratives and Theories in Natural History. In: Foundations of complex-system theories: in economics, evolutionary biology, and statistical physics. Cambridge, U.K.; New York: Cambridge University Press.[page needed]
^Blechschmidt, Erich (1977) The Beginnings of Human Life. Springer-Verlag Inc., p. 32: "The so-called basic law of biogenetics is wrong. No buts or ifs can mitigate this fact. It is not even a tiny bit correct or correct in a different form, making it valid in a certain percentage. It is totally wrong."
^Ehrlich, Paul; Richard Holm; Dennis Parnell (1963) The Process of Evolution. New York: McGraw–Hill, p. 66: "Its shortcomings have been almost universally pointed out by modern authors, but the idea still has a prominent place in biological mythology. The resemblance of early vertebrate embryos is readily explained without resort to mysterious forces compelling each individual to reclimb its phylogenetic tree."
^Tillyard, R. J (2012). "A New Classification of the Order Perlaria". The Canadian Entomologist. 53 (2): 35–43.
doi:
10.4039/Ent5335-2.
S2CID90171163.
^Hennig, Willi (1950). Grundzüge einer Theorie der Phylogenetischen Systematik [Basic features of a theory of phylogenetic systematics] (in German). Berlin: Deutscher Zentralverlag.
OCLC12126814.[page needed]
^Wagner, Warren Herbert (1952). "The fern genus Diellia: structure, affinities, and taxonomy". University of California Publications in Botany. 26 (1–6): 1–212.
OCLC4228844.
^Cain, A. J; Harrison, G. A (2009). "Phyletic Weighting". Proceedings of the Zoological Society of London. 135 (1): 1–31.
doi:
10.1111/j.1469-7998.1960.tb05828.x.
^Wilson, Edward O (1965). "A Consistency Test for Phylogenies Based on Contemporaneous Species". Systematic Zoology. 14 (3): 214–20.
doi:
10.2307/2411550.
JSTOR2411550.
^Hennig. W. (1966). Phylogenetic systematics. Illinois University Press, Urbana.[page needed]
^Farris, James S (1969). "A Successive Approximations Approach to Character Weighting". Systematic Zoology. 18 (4): 374–85.
doi:
10.2307/2412182.
JSTOR2412182.
^
abKluge, A. G; Farris, J. S (1969). "Quantitative Phyletics and the Evolution of Anurans". Systematic Biology. 18 (1): 1–32.
doi:
10.1093/sysbio/18.1.1.
^Quesne, Walter J. Le (1969). "A Method of Selection of Characters in Numerical Taxonomy". Systematic Zoology. 18 (2): 201–205.
doi:
10.2307/2412604.
JSTOR2412604.
^Farris, J. S (1970). "Methods for Computing Wagner Trees". Systematic Biology. 19: 83–92.
doi:
10.1093/sysbio/19.1.83.
^Fitch, W. M (1971). "Toward Defining the Course of Evolution: Minimum Change for a Specific Tree Topology". Systematic Biology. 20 (4): 406–16.
doi:
10.1093/sysbio/20.4.406.
JSTOR2412116.
^Adams, E. N (1972). "Consensus Techniques and the Comparison of Taxonomic Trees". Systematic Biology. 21 (4): 390–397.
doi:
10.1093/sysbio/21.4.390.
^Farris, James S (1976). "Phylogenetic Classification of Fossils with Recent Species". Systematic Zoology. 25 (3): 271–282.
doi:
10.2307/2412495.
JSTOR2412495.
^Farris, J. S (1977). "Phylogenetic Analysis Under Dollo's Law". Systematic Biology. 26: 77–88.
doi:
10.1093/sysbio/26.1.77.
^Nelson, G (1979). "Cladistic Analysis and Synthesis: Principles and Definitions, with a Historical Note on Adanson's Familles Des Plantes (1763-1764)". Systematic Biology. 28: 1–21.
doi:
10.1093/sysbio/28.1.1.
^Efron B. (1979). Bootstrap methods: another look at the jackknife. Ann. Stat. 7: 1–26.
^Margush, T; McMorris, F (1981). "Consensus-trees". Bulletin of Mathematical Biology. 43 (2): 239.
doi:
10.1016/S0092-8240(81)90019-7 (inactive 15 February 2024).{{
cite journal}}: CS1 maint: DOI inactive as of February 2024 (
link)
^Sokal, Robert R; Rohlf, F. James (1981). "Taxonomic Congruence in the Leptopodomorpha Re-Examined". Systematic Zoology. 30 (3): 309.
doi:
10.2307/2413252.
JSTOR2413252.
^Archie, James W (1989). "Homoplasy Excess Ratios: New Indices for Measuring Levels of Homoplasy in Phylogenetic Systematics and a Critique of the Consistency Index". Systematic Zoology. 38 (3): 253–269.
doi:
10.2307/2992286.
JSTOR2992286.
^D. L. Swofford and G. J. Olsen. 1990. Phylogeny reconstruction. In D. M. Hillis and G. Moritz (eds.), Molecular Systematics, pages 411–501. Sinauer Associates, Sunderland, Mass.
^Wilkinson, M (1994). "Common Cladistic Information and its Consensus Representation: Reduced Adams and Reduced Cladistic Consensus Trees and Profiles". Systematic Biology. 43 (3): 343–368.
doi:
10.1093/sysbio/43.3.343.
^Wilkinson, Mark (1995). "More on Reduced Consensus Methods". Systematic Biology. 44 (3): 435–439.
doi:
10.2307/2413604.
JSTOR2413604.
Baum, David A.; Smith, Stacey D. (2013). Tree Thinking: an introduction to phylogenetic biology. Greenwood Village, CO: Roberts and Company.
ISBN978-1-936221-16-5.
OCLC767565978.
The tips of a phylogenetic tree can be living
taxa or
fossils, and represent the "end" or the present time in an evolutionary lineage. A phylogenetic diagram can be rooted or unrooted. A rooted tree diagram indicates the hypothetical
common ancestor of the tree. An unrooted tree diagram (a network) makes no assumption about the ancestral line, and does not show the origin or "root" of the taxa in question or the direction of inferred evolutionary transformations.[5]
In addition to their use for inferring phylogenetic patterns among taxa, phylogenetic analyses are often employed to represent relationships among genes or individual organisms. Such uses have become central to understanding
biodiversity, evolution,
ecology, and
genomes.
Phylogenetics is component of
systematics that uses similarities and differences of the characteristics of species to interpret their evolutionary relationships and origins. Phylogenetics focuses on whether the characteristics of a species reinforce a phylogenetic inference that it diverged from the most recent common ancestor of a taxonomic group.[6]
In the field of
cancer research, phylogenetics can be used to study the clonal evolution of
tumors and molecular
chronology, predicting and showing how cell populations vary throughout the progression of the disease and during treatment, using whole
genome sequencing techniques.[7] The evolutionary processes behind cancer progression are quite different from those in species and are important to phylogenetic inference; these differences manifest in at least four areas: the types of aberrations that occur, the rates of
mutation, the intensity, and high heterogeneity - variability - of tumor cell subclones.[8]
Phylogenetics can also aid in
drug design and discovery. Phylogenetics allows scientists to organize species and can show which species are likely to have inherited particular traits that are medically useful, such as producing biologically active compounds - those that have effects on the human body. For example, in drug discovery,
venom-producing animals are particularly useful. Venoms from these animals produce several important drugs, e.g.,
ACE inhibitors and Prialt (
Ziconotide). To find new venoms, scientists turn to phylogenetics to screen for closely related species that may have the same useful traits. The phylogenetic tree shows which species of
fish have an origin of venom, and related fish they may contain the trait. Using this approach in studying venomous fish, biologists are able to identify the fish species that may be venomous. Biologist have used this approach in many species such as snakes and lizards.[9]
In
forensic science, phylogenetic tools are useful to assess DNA evidence for court cases. The simple phylogenetic tree of viruses A-E shows the relationships between viruses e.g., all viruses are descendants of Virus A.
HIV forensics uses phylogenetic analysis to track the differences in HIV genes and determine the relatedness of two samples. Phylogenetic analysis has been used in criminal trials to exonerate or hold individuals. HIV forensics does have its limitations, i.e., it cannot be the sole proof of transmission between individuals and phylogenetic analysis which shows transmission relatedness does not indicate direction of transmission.[10]
One small clade of fish, showing how venom has evolved multiple times.[9]
Taxonomy is the identification, naming, and
classification of organisms. Compared to systemization, classification emphasizes whether a species has characteristics of a taxonomic group.[6] The
Linnaean classification system developed in the 1700s by
Carolus Linnaeus is the foundation for modern classification methods. Linnaean classification relies on an organism's phenotype or physical characteristics to group and organize species.[11] With the emergence of
biochemistry, organism classifications are now usually based on phylogenetic data, and many systematists contend that only
monophyletic taxa should be recognized as named groups. The degree to which classification depends on inferred evolutionary history differs depending on the school of taxonomy:
phenetics ignores phylogenetic speculation altogether, trying to represent the similarity between organisms instead;
cladistics (phylogenetic systematics) tries to reflect phylogeny in its classifications by only recognizing groups based on shared, derived characters (
synapomorphies);
evolutionary taxonomy tries to take into account both the branching pattern and "degree of difference" to find a compromise between them.
Phenetics, popular in the mid-20th century but now largely obsolete, used
distance matrix-based methods to construct trees based on overall similarity in
morphology or similar observable traits (i.e. in the
phenotype or the
overall similarity of DNA, not the
DNA sequence), which was often assumed to approximate phylogenetic relationships.
Prior to 1950, phylogenetic inferences were generally presented as
narrative scenarios. Such methods are often ambiguous and lack explicit criteria for evaluating alternative hypotheses.[13][14][15]
Impacts of taxon sampling
In phylogenetic analysis, taxon sampling selects a small group of taxa to represent the evolutionary history of its broader population.[16] This process is also known as
stratified sampling or clade-based sampling.[17] The practice occurs given limited resources to compare and analyze every species within a target population.[16] Based on the representative group selected, the construction and accuracy of phylogenetic trees vary, which impacts derived phylogenetic inferences.[17]
Unavailable datasets, such as an organism's incomplete DNA and protein amino acid sequences in genomic databases, directly restrict taxonomic sampling.[17] Consequently, a significant source of
error within phylogenetic analysis occurs due to inadequate taxon samples. Accuracy may be improved by increasing the number of genetic samples within its monophyletic group. Conversely, increasing sampling from outgroups extraneous to the target stratified population may decrease accuracy.
Long branch attraction is an attributed theory for this occurrence, where nonrelated branches are incorrectly classified together, insinuating a shared evolutionary history.[16]
Percentage of inter-ordinal branches reconstructed with a constant number of bases and four phylogenetic tree construction models; neighbor-joining (NJ), minimum evolution (ME), unweighted maximum parsimony (MP), and maximum likelihood (ML). Demonstrates phylogenetic analysis with fewer taxa and more genes per taxon matches more often with the replicable consensus tree. The dotted line demonstrates an equal accuracy increase between the two taxon sampling methods. Figure is property of Michael S. Rosenberg and Sudhir Kumar as presented in the journal article Taxon Sampling, Bioinformatics, and Phylogenomics.[17]
There are debates if increasing the number of taxa sampled improves phylogenetic accuracy more than increasing the number of genes sampled per taxon. Differences in each method's sampling impact the number of nucleotide sites utilized in a sequence alignment, which may contribute to disagreements. For example, phylogenetic trees constructed utilizing a more significant number of total nucleotides are generally more accurate, as supported by phylogenetic trees' bootstrapping replicability from random sampling.
The graphic presented in Taxon Sampling, Bioinformatics, and Phylogenomics, compares the correctness of phylogenetic trees generated using fewer taxa and more sites per taxon on the x-axis to more taxa and fewer sites per taxon on the y-axis. With fewer taxa, more genes are sampled amongst the taxonomic group; in comparison, with more taxa added to the taxonomic sampling group, fewer genes are sampled. Each method has the same total number of nucleotide sites sampled. Furthermore, the dotted line represents a 1:1 accuracy between the two sampling methods. As seen in the graphic, most of the plotted points are located below the dotted line, which indicates gravitation toward increased accuracy when sampling fewer taxa with more sites per taxon. The research performed utilizes four different phylogenetic tree construction models to verify the theory; neighbor-joining (NJ), minimum evolution (ME), unweighted maximum parsimony (MP), and maximum likelihood (ML). In the majority of models, sampling fewer taxon with more sites per taxon demonstrated higher accuracy.
Generally, with the alignment of a relatively equal number of total nucleotide sites, sampling more genes per taxon has higher bootstrapping replicability than sampling more taxa. However, unbalanced datasets within genomic databases make increasing the gene comparison per taxon in uncommonly sampled organisms increasingly difficult.[17]
History
Overview
The term "phylogeny" derives from the German Phylogenie, introduced by Haeckel in 1866,[18] and the
Darwinian approach to classification became known as the "phyletic" approach.[19] It can be traced back to
Aristotle, who wrote in his Posterior Analytics, "We may assume the superiority ceteris paribus [other things being equal] of the demonstration which derives from fewer postulates or hypotheses."
Ernst Haeckel's recapitulation theory
The modern concept of phylogenetics evolved primarily as a disproof of a previously widely accepted theory. During the late 19th century,
Ernst Haeckel's
recapitulation theory, or "biogenetic fundamental law", was widely accepted. It was often expressed as "
ontogeny recapitulates phylogeny", i.e. the development of a single organism during its lifetime, from germ to adult, successively mirrors the adult stages of successive ancestors of the species to which it belongs. But this theory has long been rejected.[20][21] Instead,
ontogeny evolves – the phylogenetic history of a species cannot be read directly from its ontogeny, as Haeckel thought would be possible, but characters from ontogeny can be (and have been) used as data for phylogenetic analyses; the more closely related two species are, the more
apomorphies their embryos share.
Timeline of key points
Branching tree diagram from Heinrich Georg Bronn's work (1858)Phylogenetic tree suggested by Haeckel (1866)
14th century, lex parsimoniae (
parsimony principle),
William of Ockam, English philosopher, theologian, and Franciscan friar, but the idea actually goes back to
Aristotle, as a precursor concept. He introduced the concept of
Occam's razor, which is the problem solving principle that recommends searching for explanations constructed with the smallest possible set of elements. Though he did not use these exact words, the principle can be summarized as "Entities must not be multiplied beyond necessity." The principle advocates that when presented with competing hypotheses about the same prediction, one should prefer the one that requires fewest assumptions.
1763,
Bayesian probability, Rev. Thomas Bayes,[22] a precursor concept. Bayesian probability began a resurgence in the 1950s, allowing scientists in the computing field to pair traditional Bayesian statistics with other more modern techniques. It is now used as a blanket term for several related interpretations of probability as an amount of epistemic confidence.
18th century, Pierre Simon (Marquis de Laplace), perhaps first to use ML (maximum likelihood), precursor concept. His work gave way to the
Laplace distribution, which can be directly linked to
least absolute deviations.
1809, evolutionary theory, Philosophie Zoologique,Jean-Baptiste de Lamarck, precursor concept, foreshadowed in the 17th century and 18th century by Voltaire, Descartes, and Leibniz, with Leibniz even proposing evolutionary changes to account for observed gaps suggesting that many species had become extinct, others transformed, and different species that share common traits may have at one time been a single race,[23] also foreshadowed by some early Greek philosophers such as
Anaximander in the 6th century BC and the atomists of the 5th century BC, who proposed rudimentary theories of evolution[24]
1837, Darwin's notebooks show an evolutionary tree[25]
1840, American Geologist Edward Hitchcock published what is considered to be the first paleontological "Tree of Life". Many critiques, modifications, and explanations would follow.[26]This chart displays one of the first published attempts at a paleontological "Tree of Life" by Geologist Edward Hitchcock. (1840)
1843, distinction between
homology and
analogy (the latter now referred to as
homoplasy), Richard Owen, precursor concept. Homology is the term used to characterize the similarity of features that can be parsimoniously explained by common ancestry. Homoplasy is the term used to describe a feature that has been gained or lost independently in separate lineages over the course of evolution.
1858, Paleontologist Heinrich Georg Bronn (1800–1862) published a hypothetical tree to illustrating the paleontological "arrival" of new, similar species. following the extinction of an older species. Bronn did not propose a mechanism responsible for such phenomena, precursor concept.[27]
1858, elaboration of evolutionary theory, Darwin and Wallace,[28] also in Origin of Species by Darwin the following year, precursor concept.
1866,
Ernst Haeckel, first publishes his phylogeny-based evolutionary tree, precursor concept. Haeckel introduces the now-disproved recapitulation theory.
1893,
Dollo's Law of Character State Irreversibility,[29] precursor concept. Dollo's Law of Irreversibility states that "an organism never comes back exactly to its previous state due to the indestructible nature of the past, it always retains some trace of the transitional stages through which it has passed."[30]
1912, ML (maximum likelihood recommended, analyzed, and popularized by
Ronald Fisher, precursor concept. Fisher is one of the main contributors to the early 20th-century revival of Darwinism, and has been called the "greatest of Darwin's successors" for his contributions to the revision of the theory of evolution and his use of mathematics to combine
Mendelian genetics and
natural selection in the
20th century "modern synthesis".
1921, Tillyard uses term "phylogenetic" and distinguishes between archaic and specialized characters in his classification system.[31]
1949,
Jackknife resampling, Maurice Quenouille (foreshadowed in '46 by Mahalanobis and extended in '58 by Tukey), precursor concept.
1950,
Willi Hennig's classic formalization.[32] Hennig is considered the founder of phylogenetic systematics, and published his first works in German of this year. He also asserted a version of the parsimony principle, stating that the presence of amorphous characters in different species 'is always reason for suspecting kinship, and that their origin by convergence should not be presumed a priori'. This has been considered a foundational view of
phylogenetic inference.
1952, William Wagner's ground plan divergence method.[33]
1960, "cladistic" coined by Cain and Harrison.[35]
1963, first attempt to use ML (maximum likelihood) for phylogenetics, Edwards and Cavalli-Sforza.[36]
1965
Camin-Sokal parsimony, first parsimony (optimization) criterion and first computer program/algorithm for cladistic analysis both by Camin and Sokal.[37]
Character compatibility method, also called clique analysis, introduced independently by Camin and Sokal (loc. cit.) and
E. O. Wilson.[38]
First successful application of ML (maximum likelihood) to phylogenetics (for protein sequences), Neyman.[44]
Fitch parsimony, Walter M. Fitch.[45] These gave way to the most basic ideas of
maximum parsimony. Fitch is known for his work on reconstructing phylogenetic trees from protein and DNA sequences. His definition of
orthologous sequences has been referenced in many research publications.
NNI (nearest neighbour interchange), first branch-swapping search strategy, developed independently by Robinson[46] and Moore et al.
ME (minimum evolution), Kidd and Sgaramella-Zonta[47] (it is unclear if this is the pairwise distance method or related to ML as Edwards and Cavalli-Sforza call ML "minimum evolution").
1980,
PHYLIP, first software package for phylogenetic analysis,
Joseph Felsenstein. A free computational phylogenetics package of programs for inferring evolutionary trees (
phylogenies). One such example tree created by PHILYP, called a "drawgram", generates rooted trees. This image shown in the figure below shows the evolution of phylogenetic trees over time.
Strict consensus, Sokal and Rohlf[55]This image depicts a PHILYP generated drawgram. This drawgram is an example of one of the possible trees the software is capable of generating.first computationally efficient ML (maximum likelihood) algorithm.[56] Felsenstein created the Felsenstein Maximum Likelihood method, used for the inference of phylogeny which evaluates a hypothesis about evolutionary history in terms of the probability that the proposed model and the hypothesized history would give rise to the observed data set.
1996, first working methods for BI (Bayesian Inference) independently developed by Li,[72] Mau,[73] and Rannala and Yang[74] and all using MCMC (Markov chain-Monte Carlo).
1998, TNT (Tree Analysis Using New Technology), Goloboff, Farris, and Nixon.
2004, 2005, similarity metric (using an approximation to Kolmogorov complexity) or NCD (normalized compression distance), Li et al.,[76] Cilibrasi and Vitanyi.[77]
Phylogenetic tools and representations (trees and networks) can also be applied to
philology, the study of the evolution of oral languages and written text and manuscripts, such as in the field of
quantitative comparative linguistics.[79]
Computational phylogenetics can be used to investigate a language as an evolutionary system. The evolution of human language closely corresponds with human's biological evolution which allows phylogenetic methods to be applied. The concept of a "tree" serves as an efficient way to represent relationships between languages and language splits. It also serves as a way of testing hypotheses about the connections and ages of language families. For example, relationships among languages can be shown by using
cognates as characters.[80][81] The phylogenetic tree of Indo-European languages shows the relationships between several of the languages in a timeline, as well as the similarity between words and word order.
There are three types of criticisms about using phylogenetics in philology, the first arguing that languages and species are different entities, therefore you can not use the same methods to study both. The second being how phylogenetic methods are being applied to linguistic data. And the third, discusses the types of data that is being used to construct the trees.[80]
Bayesian phylogenetic methods, which are sensitive to how treelike the data is, allow for the reconstruction of relationships among languages, locally and globally. The main two reasons for the use of Bayesian phylogenetics are that (1) diverse scenarios can be included in calculations and (2) the output is a sample of trees and not a single tree with true claim.[82]
The same process can be applied to texts and manuscripts. In
Paleography, the study of historical writings and manuscripts, texts were replicated by scribes who copied from their source and alterations - i.e., 'mutations' - occurred when the scribe did not precisely copy the source.[83]
Phylogenetic screens involve the pharmacological examination of closely related groups of organisms. Advances in
cladistics analysis through faster computer programs and improved molecular techniques have increased the precision of phylogenetic determination, allowing for the identification of species with pharmacological potential.
Phylogenetic screens have been used in a rudimentary manner in the past, such as studying the
Apocynaceae family of plants known for their alkaloid-producing species like
Catharanthus, which produces
vincristine, an antileukemia drug. However, modern techniques now enable researchers to study close relatives of a species to uncover either (1) higher abundance of important bioactive compounds (e.g., species of
Taxus for taxol) or (2) natural variants of known pharmaceuticals (e.g., species of Catharanthus for different forms of vincristine or vinblastine.[citation needed]
The figure below contains the phylogenetic screen of biodiversity within the fungi family. Inside the circle there are subtrees present that were done via phylogenetic analysis. These relations help understand the evolutionary history of various groups of organisms, identifying relationships between different species, and predicting future evolutionary changes. If we were to take biodiversity information from existing knowledge there might be relations between species or subgroups that we didn't know. But with emerging imagery systems and new analysis techniques more genetic relation can be found in biodiverse fields. The image below can help with conservation efforts as there are rare species of fungi involved, that could be beneficial to ecosystems all around.[84]
Phylogenetic Subtree of fungi containing different biodiverse sections of the fungi group.
Whole-genome sequence data of pathogens obtained from outbreaks or epidemics of infectious diseases can provide important insights into transmission dynamics and inform public health strategies. Previous studies have relied on integrating genomic and epidemiological data to reconstruct transmission events. However, recent research has explored the possibility of deducing transmission patterns solely from genomic data using
phylodynamics, which involves analyzing the properties of pathogen phylogenies. Phylodynamics uses theoretical models to compare predicted branch lengths with actual branch lengths in phylogenies to infer transmission patterns. Additionally,
coalescent theory, which describes probability distributions on trees based on population size, has been adapted for epidemiological purposes. Another potential source of information within phylogenies that has been explored is "tree shape". These approaches are computationally intensive but have the potential to provide valuable insights into pathogen transmission dynamics.[85]
Pathogen Transmission Trees
The structure of the host contact network has a profound impact on the dynamics of outbreaks or epidemics, and outbreak management strategies rely on the type of transmission patterns driving the outbreak. One can expect that pathogen genomes spreading through different contact network structures, such as chains, homogenous networks, or networks with super-spreaders, would accumulate mutations in distinct patterns, resulting in noticeable differences in the shape of phylogenetic trees, as illustrated in Fig. 1. Analyzation of the structural characteristics of phylogenetic trees generated from simulated bacterial genome evolution across multiple types of contact networks was conducted. Simple topological properties of phylogenetic trees that, when combined, can be used to classify trees into chain-like, homogenous, or super-spreading dynamics, revealing transmission dynamics. These properties form the basis of a computational classifier are used to classify real-world outbreaks. Remarkably, the computational predictions of overall transmission dynamics for each outbreak align with known epidemiology [86]
Graphical Representation of Phylogenetic Tree analysis
Different transmission networks result in quantitatively different tree shapes to determine whether tree shapes captured information about the underlying disease transmission patterns within an outbreak, we simulated evolution of a bacterial genome over three types of outbreak contact network—homogenous, super-spreading and chain—and summarized the resulting phylogenies with five metrics describing tree shape. Figures 2 and 3 illustrate the distributions of these metrics across the three types of outbreaks, revealing clear differences in tree topology depending on the underlying host contact network. Super-spreader networks gave rise to phylogenies with higher Colless imbalance, longer ladder patterns, lower Δw and deeper trees than transmission networks with a homogeneous distribution of contacts. Trees derived from chain-like networks were less variable, deeper, more imbalanced and narrower than the other trees. Other topological summary metrics considered did not resolve the three outbreak types as fully (Supplementary Information). Scatter plots can be used for pathogen transmission analysis to visualize the relationship between two variables, such as the number of infected individuals and the time since infection. For example, a scatter plot can be used to examine the relationship between the number of cases of a pathogen and the amount of time since the first case was reported. This can help to identify trends and patterns in the data, such as whether the spread of the pathogen is increasing or decreasing over time. Scatter plots can also be used to identify any outliers or clusters of data points, which can provide insight into potential transmission routes or super-spreader events. Overall, scatter plots can be a useful tool in pathogen transmission analysis to identify patterns and trends in the data, and to inform public health interventions and control measures.[86]
Pathogen Transfer Box Plot data
The
box plot imagery on the right displays the pathogen transformation data. Box plots are often used in statistical analysis to compare different groups or to visualize changes in a single group over time. They are particularly useful when dealing with large datasets or when comparing several groups, as they can quickly highlight differences or similarities in the data. Box plots, also known as box-and-whisker plots, are useful in statistical analysis to provide a summary of the distribution of a dataset. They display the range, median, quartiles, and potential outliers of the data in a visual manner. Box plots are commonly used to compare different groups or to analyze changes in a single group over time. They are especially helpful when working with large datasets or when comparing multiple groups, as they can easily identify any differences or similarities in the data. This makes box plots a valuable tool for analyzing pathogen transmission data, as they can help to identify important features in the distribution of the data.[86]
^Richard C. Brusca & Gary J. Brusca (2003). Invertebrates (2nd ed.). Sunderland, Massachusetts: Sinauer Associates.
ISBN978-0-87893-097-5.
^Bock, W. J. (2004). Explanations in systematics. Pp. 49–56. In Williams, D. M. and Forey, P. L. (eds) Milestones in Systematics. London: Systematics Association Special Volume Series 67. CRC Press, Boca Raton, Florida.
^Auyang, Sunny Y. (1998). Narratives and Theories in Natural History. In: Foundations of complex-system theories: in economics, evolutionary biology, and statistical physics. Cambridge, U.K.; New York: Cambridge University Press.[page needed]
^Blechschmidt, Erich (1977) The Beginnings of Human Life. Springer-Verlag Inc., p. 32: "The so-called basic law of biogenetics is wrong. No buts or ifs can mitigate this fact. It is not even a tiny bit correct or correct in a different form, making it valid in a certain percentage. It is totally wrong."
^Ehrlich, Paul; Richard Holm; Dennis Parnell (1963) The Process of Evolution. New York: McGraw–Hill, p. 66: "Its shortcomings have been almost universally pointed out by modern authors, but the idea still has a prominent place in biological mythology. The resemblance of early vertebrate embryos is readily explained without resort to mysterious forces compelling each individual to reclimb its phylogenetic tree."
^Tillyard, R. J (2012). "A New Classification of the Order Perlaria". The Canadian Entomologist. 53 (2): 35–43.
doi:
10.4039/Ent5335-2.
S2CID90171163.
^Hennig, Willi (1950). Grundzüge einer Theorie der Phylogenetischen Systematik [Basic features of a theory of phylogenetic systematics] (in German). Berlin: Deutscher Zentralverlag.
OCLC12126814.[page needed]
^Wagner, Warren Herbert (1952). "The fern genus Diellia: structure, affinities, and taxonomy". University of California Publications in Botany. 26 (1–6): 1–212.
OCLC4228844.
^Cain, A. J; Harrison, G. A (2009). "Phyletic Weighting". Proceedings of the Zoological Society of London. 135 (1): 1–31.
doi:
10.1111/j.1469-7998.1960.tb05828.x.
^Wilson, Edward O (1965). "A Consistency Test for Phylogenies Based on Contemporaneous Species". Systematic Zoology. 14 (3): 214–20.
doi:
10.2307/2411550.
JSTOR2411550.
^Hennig. W. (1966). Phylogenetic systematics. Illinois University Press, Urbana.[page needed]
^Farris, James S (1969). "A Successive Approximations Approach to Character Weighting". Systematic Zoology. 18 (4): 374–85.
doi:
10.2307/2412182.
JSTOR2412182.
^
abKluge, A. G; Farris, J. S (1969). "Quantitative Phyletics and the Evolution of Anurans". Systematic Biology. 18 (1): 1–32.
doi:
10.1093/sysbio/18.1.1.
^Quesne, Walter J. Le (1969). "A Method of Selection of Characters in Numerical Taxonomy". Systematic Zoology. 18 (2): 201–205.
doi:
10.2307/2412604.
JSTOR2412604.
^Farris, J. S (1970). "Methods for Computing Wagner Trees". Systematic Biology. 19: 83–92.
doi:
10.1093/sysbio/19.1.83.
^Fitch, W. M (1971). "Toward Defining the Course of Evolution: Minimum Change for a Specific Tree Topology". Systematic Biology. 20 (4): 406–16.
doi:
10.1093/sysbio/20.4.406.
JSTOR2412116.
^Adams, E. N (1972). "Consensus Techniques and the Comparison of Taxonomic Trees". Systematic Biology. 21 (4): 390–397.
doi:
10.1093/sysbio/21.4.390.
^Farris, James S (1976). "Phylogenetic Classification of Fossils with Recent Species". Systematic Zoology. 25 (3): 271–282.
doi:
10.2307/2412495.
JSTOR2412495.
^Farris, J. S (1977). "Phylogenetic Analysis Under Dollo's Law". Systematic Biology. 26: 77–88.
doi:
10.1093/sysbio/26.1.77.
^Nelson, G (1979). "Cladistic Analysis and Synthesis: Principles and Definitions, with a Historical Note on Adanson's Familles Des Plantes (1763-1764)". Systematic Biology. 28: 1–21.
doi:
10.1093/sysbio/28.1.1.
^Efron B. (1979). Bootstrap methods: another look at the jackknife. Ann. Stat. 7: 1–26.
^Margush, T; McMorris, F (1981). "Consensus-trees". Bulletin of Mathematical Biology. 43 (2): 239.
doi:
10.1016/S0092-8240(81)90019-7 (inactive 15 February 2024).{{
cite journal}}: CS1 maint: DOI inactive as of February 2024 (
link)
^Sokal, Robert R; Rohlf, F. James (1981). "Taxonomic Congruence in the Leptopodomorpha Re-Examined". Systematic Zoology. 30 (3): 309.
doi:
10.2307/2413252.
JSTOR2413252.
^Archie, James W (1989). "Homoplasy Excess Ratios: New Indices for Measuring Levels of Homoplasy in Phylogenetic Systematics and a Critique of the Consistency Index". Systematic Zoology. 38 (3): 253–269.
doi:
10.2307/2992286.
JSTOR2992286.
^D. L. Swofford and G. J. Olsen. 1990. Phylogeny reconstruction. In D. M. Hillis and G. Moritz (eds.), Molecular Systematics, pages 411–501. Sinauer Associates, Sunderland, Mass.
^Wilkinson, M (1994). "Common Cladistic Information and its Consensus Representation: Reduced Adams and Reduced Cladistic Consensus Trees and Profiles". Systematic Biology. 43 (3): 343–368.
doi:
10.1093/sysbio/43.3.343.
^Wilkinson, Mark (1995). "More on Reduced Consensus Methods". Systematic Biology. 44 (3): 435–439.
doi:
10.2307/2413604.
JSTOR2413604.
Baum, David A.; Smith, Stacey D. (2013). Tree Thinking: an introduction to phylogenetic biology. Greenwood Village, CO: Roberts and Company.
ISBN978-1-936221-16-5.
OCLC767565978.













 The dictionary definition of
phylogenetics at Wiktionary
The dictionary definition of
phylogenetics at Wiktionary